
Large Language Models (LLMs) have demonstrated an impressive ability to generate human-like text, revolutionizing how we interact with AI. However, LLMs possess a significant limitation: their knowledge is confined to the data they were trained on. This means they can struggle with specific, niche, or rapidly evolving topics, sometimes even fabricating information—a phenomenon known as "hallucination." Retrieval Augmented Generation (RAG) offers a solution, empowering LLMs by connecting them to external knowledge sources.
1. How RAG works
RAG pipelines operate through a series of coordinated steps. First, the source material, whether it be a collection of documents or a database, undergoes an indexing process. This begins with chunking, where the data is divided into smaller, manageable segments. These chunks are then transformed into numerical representations called embeddings using a specialized model. These embeddings, along with the original content of the chunks, are stored in a vector database.
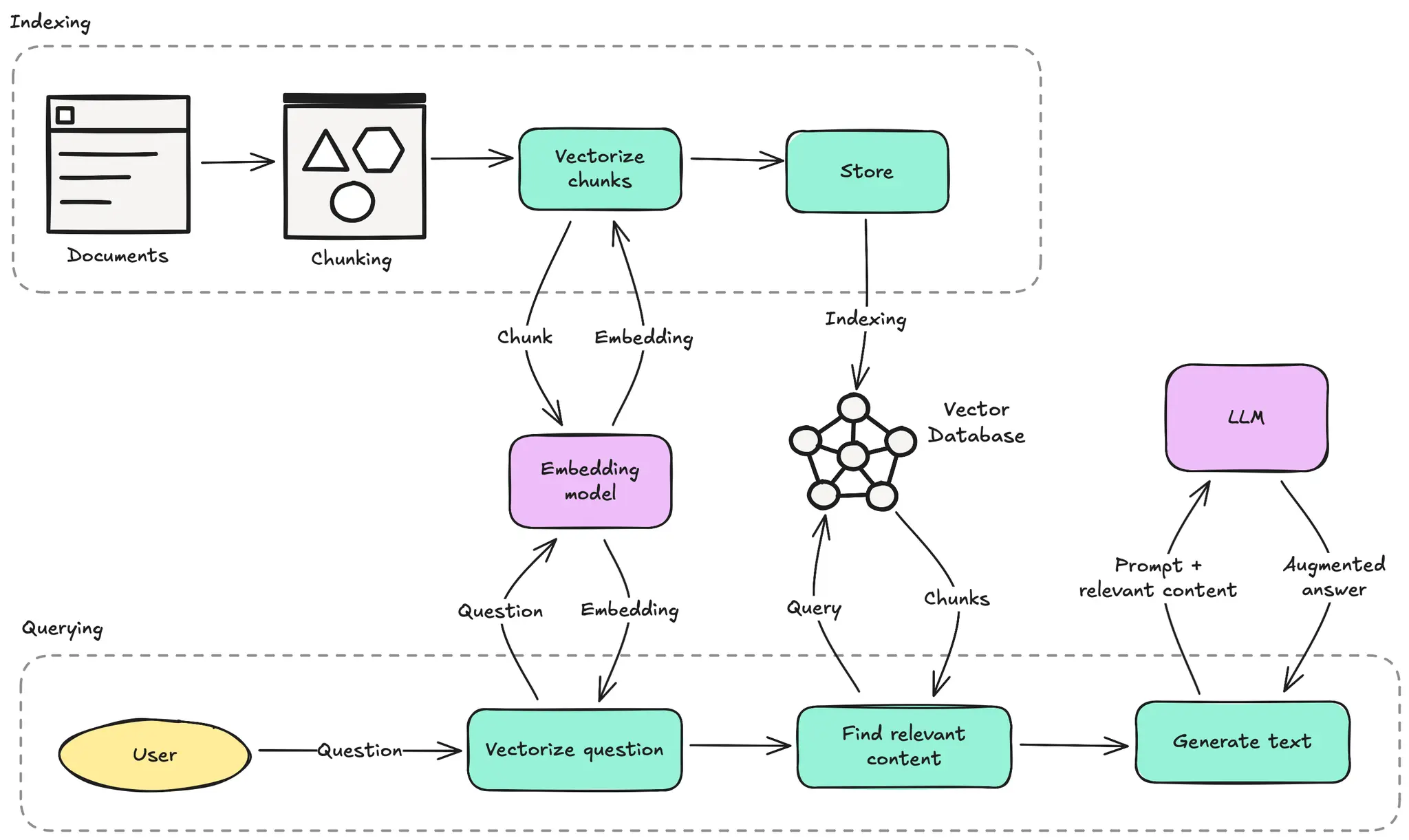
When a user poses a query, the RAG system initiates the querying phase. The user's question is also converted into an embedding using the same model used during indexing. This query embedding is then used to search the vector database for the most similar stored embeddings. Similarity is typically measured using cosine similarity, defined as:
where and are vector representations of the query and stored document chunks. A higher cosine similarity indicates greater relevance.
The retrieved chunks are then combined with the original user query, forming an augmented prompt. This augmented prompt is passed to the LLM during the generation step. Because the LLM now has access to specific, relevant information retrieved from the knowledge base, it can generate a far more accurate, contextually appropriate, and informative response.
RAG vs. Fine-Tuning
While RAG enhances LLM capabilities by integrating external knowledge dynamically, an alternative approach is fine-tuning, where the model is retrained with additional domain-specific data. Below is a comparison:
| Feature | RAG | Fine-Tuning |
|---|---|---|
| Flexibility | Dynamic updates with external data | Requires retraining for updates |
| Cost | Lower computational cost | Expensive, requires GPUs |
| Accuracy | Context-aware, avoids hallucination | Can generalize better in some cases |
| Latency | Slightly slower (retrieval overhead) | Faster response time |
RAG is preferable when real-time updates and external knowledge integration are required, whereas fine-tuning is more suitable for static, well-defined knowledge domains.
Scalability Considerations
For large knowledge bases, efficient retrieval is crucial. Maintaining speed and accuracy when searching numerous embeddings is a key challenge. Techniques like Approximate Nearest Neighbor (ANN) search, using algorithms such as HNSW, can significantly reduce retrieval time, trading slight accuracy for speed. Index compression reduces vector storage size and can improve performance, provided accuracy isn't compromised. Hierarchical clustering, by organizing embeddings hierarchically, enables faster searches within large datasets.
2. Building a RAG Pipeline with Node.js
Let's explore a practical implementation of a RAG pipeline using Node.js, the Vercel AI SDK, Upstash Vector database, and Mistral AI.
Configuring providers
First, we need to set up the providers for the embedding model, the LLM model, and the vector database.
typescriptimport {Index} from '@upstash/vector'; import {mistral} from '@ai-sdk/mistral'; import {config} from 'dotenv'; config(); export const index = new Index({ url: process.env.UPSTASH_URL, token: process.env.UPSTASH_TOKEN }); export const embeddingModel = mistral.embedding('mistral-embed'); export const llmModel = mistral('mistral-large-latest');
Indexing Your Data
The indexing process starts with reading your data, in this case, from a text file. The generateChunks function splits
this text into smaller chunks based on sentence boundaries. The generateEmbeddings function then uses the Mistral
embedding model via the AI SDK to create vector embeddings for each chunk. Finally, the embed function stores
these embeddings, along with the original chunk content as metadata, into the database.
typescriptimport {embedMany} from 'ai'; import {embeddingModel, index} from './providers.ts'; import * as fs from 'node:fs'; // Split the input text into chunks based on sentence boundaries function generateChunks(input: string): string[] { return input .trim() .split('.') .filter(i => i !== ''); }; async function generateEmbeddings(value: string): Promise<Array<{ embedding: number[]; content: string }>> { const chunks = generateChunks(value); const {embeddings} = await embedMany({ model: embeddingModel, values: chunks }); return embeddings.map((e, i) => ({content: chunks[i], embedding: e})); }; async function embed(value: string) { const data = await generateEmbeddings(value); for (const {embedding, content} of data) { await index.upsert({ id: crypto.randomUUID(), vector: embedding, metadata: {value: content} }); } } const data = fs.readFileSync('data.txt', 'utf-8'); await embed(data);
Querying for Relevant Information
When a user asks a question, the findRelevantContent function converts the question into an embedding using the same
Mistral model. It then queries the database to find the most similar embeddings, effectively retrieving
the most relevant chunks of information.
typescriptimport {type CoreMessage, embed, generateText, tool} from 'ai'; import {embeddingModel, index, llmModel} from './providers.ts'; import {z} from 'zod'; const MIN_SIMILARITY = 0.8; const TOP_K = 5; export async function generateEmbedding(value: string): Promise<number[]> { const input = value.replaceAll('\\n', ' '); const {embedding} = await embed({ model: embeddingModel, value: input }); return embedding; } export async function findRelevantContent(userQuery: string) { const userQueryEmbedded = await generateEmbedding(userQuery); const chunk = await index.query({ vector: userQueryEmbedded, topK: TOP_K, includeVectors: true, includeMetadata: true }); if (chunk.length === 0) { return []; } return chunk.filter(({score}) => score > MIN_SIMILARITY); }
The TOP_K constant determines how many relevant chunks to retrieve, while the MIN_SIMILARITY constant sets the
threshold for relevance. Chunks with a similarity score below this threshold are discarded.
Generating the Final Answer
The generateAnswer function takes the user's question and the retrieved relevant chunks. It constructs a prompt that
includes both the question and the relevant context, then sends this augmented prompt to the Mistral LLM.
The model generates a response by using the getInformation tool.
typescriptasync function generateAnswer(messages: CoreMessage[]) { const res = await generateText({ model: llmModel, messages, system: `You are a helpful assistant. Check your knowledge base before answering any questions. Only respond to questions using information from tool calls. if no relevant information is found in the tool calls, respond, "Sorry, I cannot answer this question.". Respond with a small answer with max 20 words.`, maxSteps: 2, tools: { getInformation: tool({ description: `get information from your knowledge base to answer questions.`, parameters: z.object({ question: z.string().describe('the users question') }), execute: async ({question}) => { const res = await findRelevantContent(question); if (res.length === 0) { return 'No relevant information found.'; } return res.map(({metadata}) => metadata?.value).join(' '); } }) } }); return res.text; }
Conclusion
RAG is a transformative technique that addresses the inherent limitations of LLMs by grounding them in real-world knowledge. By connecting LLMs to external data sources, RAG significantly enhances their accuracy, relevance, and trustworthiness.