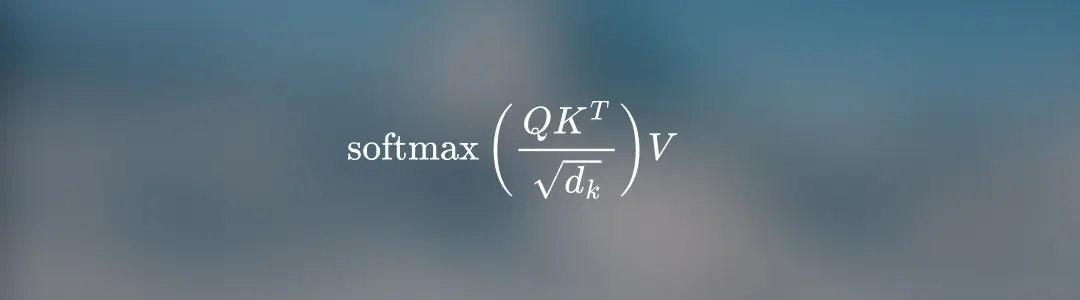
Transformers have revolutionized the field of Natural Language Processing (NLP), becoming the foundation for many state-of-the-art models such as BERT, GPT, and T5. Introduced in the seminal paper "Attention is All You Need" in 2017, the transformer architecture addresses key limitations of earlier sequence-based models, offering unparalleled scalability, efficiency, and performance. This article dives into the inner workings of transformers, providing an in-depth exploration of their architecture, mechanisms, and key advantages over traditional Recurrent Neural Networks (RNNs).
Introduction to Transformers
A transformer is a deep learning model designed to process sequential data, such as text, by leveraging self-attention mechanisms. Unlike RNNs, transformers do not rely on sequential processing but instead process the entire input sequence simultaneously, allowing for parallel computation and faster training. Transformers have applications in a wide range of domains, from language translation to image generation and protein folding.
Advantages Over RNNs
- Parallel Processing: Unlike RNNs, transformers process the entire input sequence simultaneously, enabling parallel computation and faster training times.
- Long-Range Dependencies: Transformers mitigate the vanishing gradient problem through self-attention mechanisms, allowing the model to weigh the importance of each token in the sequence relative to others, regardless of their distance.
- Contextual Understanding: Transformers, with their multi-head self-attention and positional encoding, provide a more comprehensive contextual understanding and scale more efficiently with larger datasets.
Transformer Architecture Overview
The transformer architecture is composed of two primary components: the encoder and the decoder. Each of these components is constructed from a stack of identical layers, with each layer containing specific sub-blocks dedicated to self-attention, feed-forward networks, and normalization.
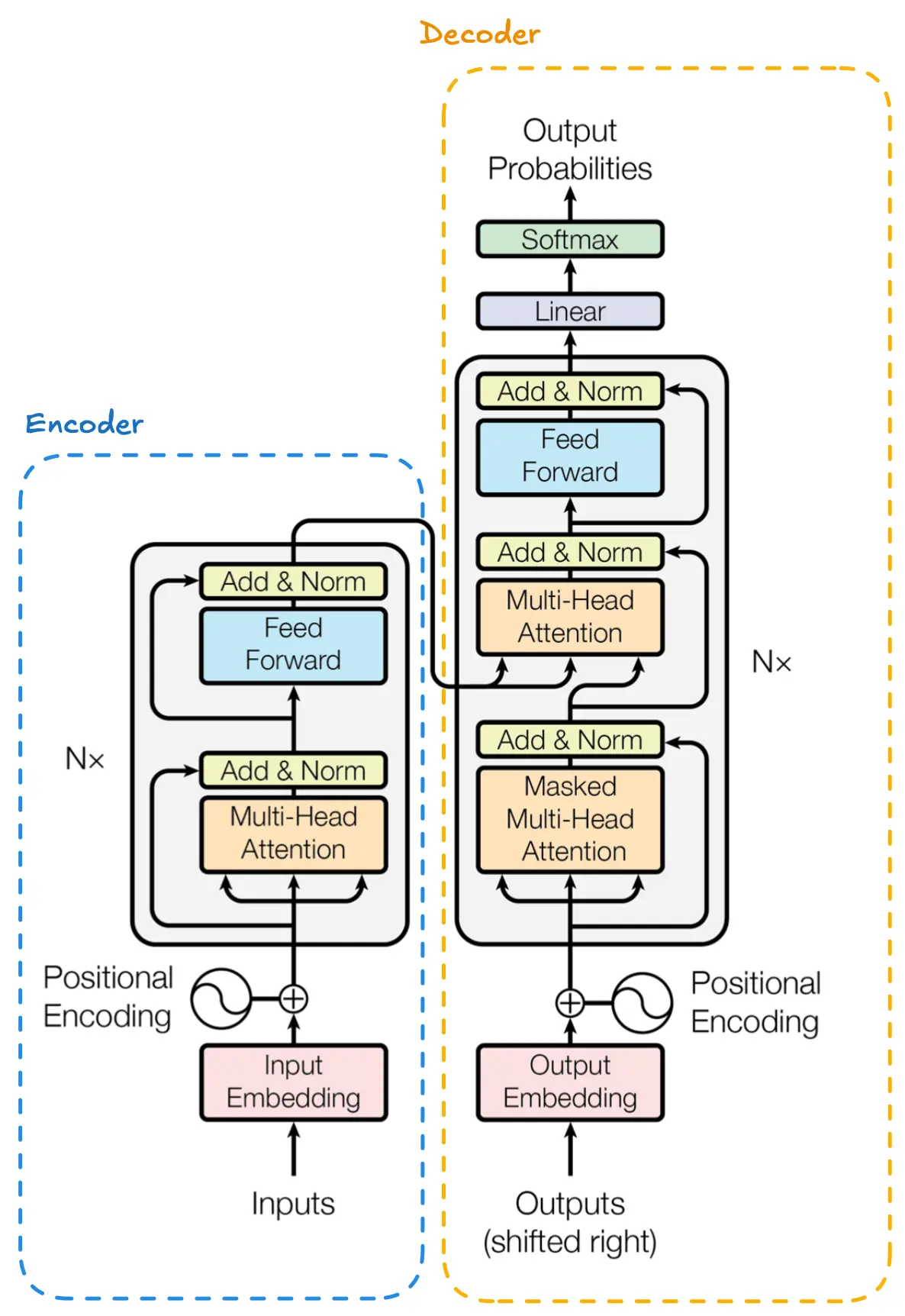
Encoder and Decoder Structure
Encoder
The encoder is responsible for processing the input sequence and producing a sequence of continuous representations. These representations capture the contextual information of the input tokens. The encoder is non-masked, meaning it can see the entire input sequence at once. This makes the encoder particularly useful for tasks that require analyzing the entire sequence, such as classification tasks.
Decoder
The decoder generates the output sequence by attending to the encoder’s representations and the previously generated tokens. The decoder is masked and autoregressive, meaning it generates one token at a time based on the previously generated tokens. This makes the decoder ideal for tasks that involve generating sequences, such as text generation or audio synthesis.
Combined Use: Sequence-to-Sequence Tasks
In sequence-to-sequence tasks, both the encoder and decoder are used together. The encoder processes the input sequence and produces a context-aware representation, which is then used by the decoder to generate the output sequence. This combined use is particularly powerful for tasks like machine translation, where the encoder processes the input sentence in one language, and the decoder generates the translated sentence in another language. Another example is image captioning, where the encoder processes an image to produce a contextual representation, and the decoder generates a descriptive caption for the image.
A notable application of sequence-to-sequence tasks is Stable Diffusion, a text-to-image model that generates images from textual descriptions. The encoder processes the input text to produce a contextual representation, and the decoder generates the corresponding image.
Core Components of Transformers
Transformers rely on a modular design, combining attention mechanisms and feed-forward layers to model complex relationships in data. This flexibility makes them ideal for diverse tasks like translation and text generation. The next sections will explain the different blocks that make up the transformer architecture.
Tokenization
Before the input sequence can be processed by the transformer, it must be tokenized. Tokenization is the process of splitting text into individual tokens, which can be words, subwords, or even characters. This step is crucial because it converts the raw text into a format that the model can understand and process.
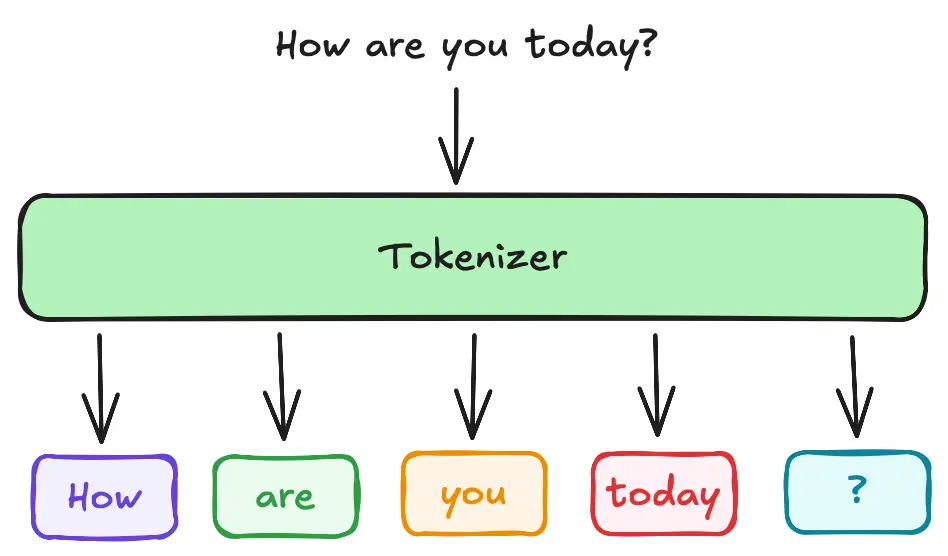
In the original "Attention is All You Need" paper, the authors used a byte pair encoding (BPE) tokenizer, which splits words into subword units. This approach helps to handle out-of-vocabulary words by breaking them down into known subwords. The tokenizer converts the input text into a sequence of tokens, which are then mapped to their corresponding embeddings.
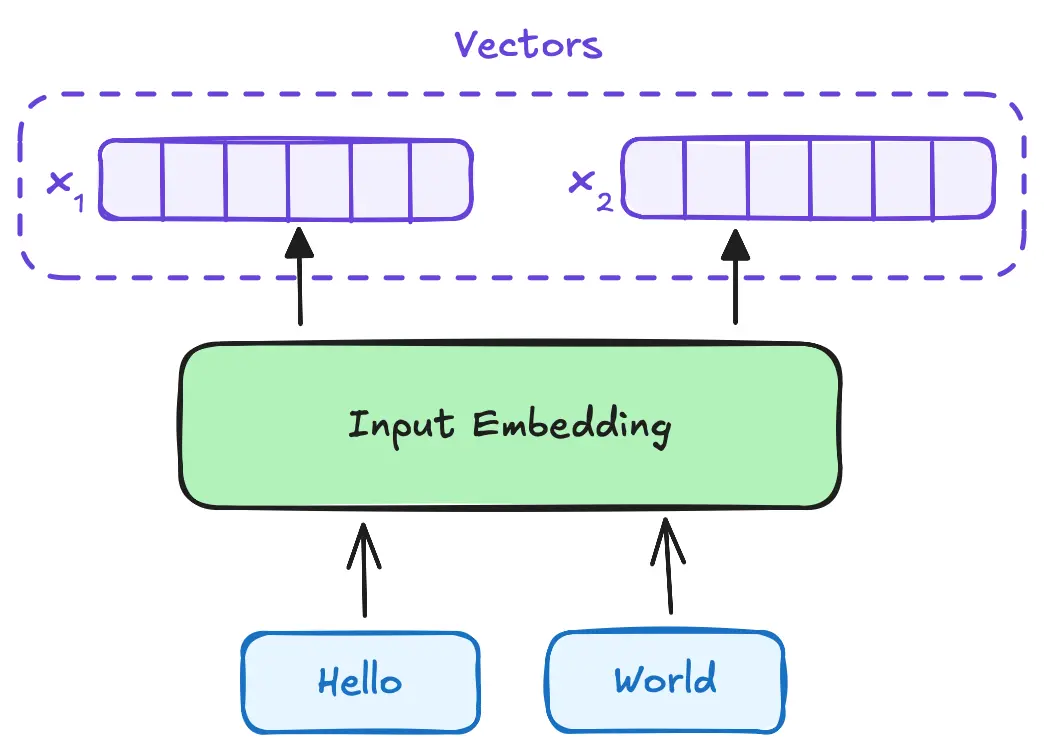
Input Embedding
The first step in processing the input sequence is to convert the discrete tokens into continuous vector representations. This is achieved through input embedding, where each token is mapped to a dense vector of fixed size. These embeddings capture semantic information about the tokens and are learned during the training process. The embedding layer transforms each token into a vector of dimension , which is a hyperparameter of the model. This vector representation allows the model to perform mathematical operations on the tokens, enabling the capture of complex relationships between them.
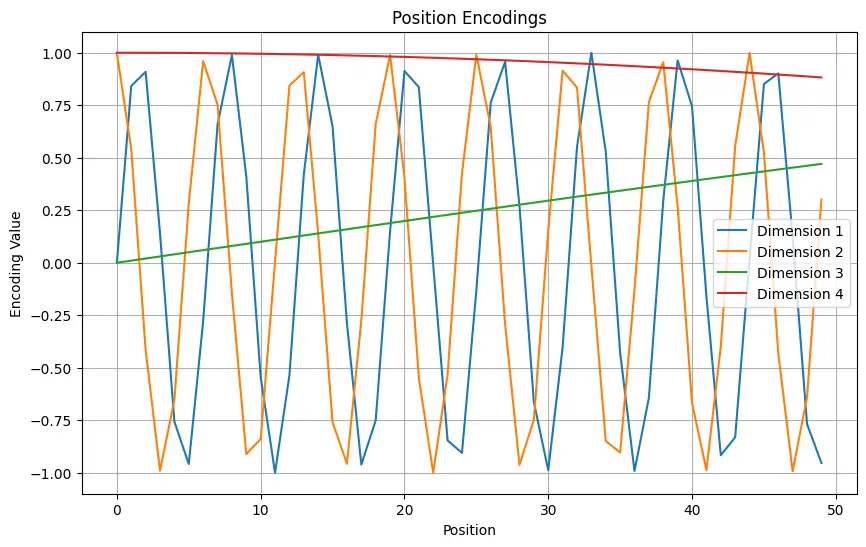
Positional Encoding
Since transformers process the entire sequence simultaneously, they lack the inherent notion of order present in RNNs. To incorporate the positional information of tokens, positional encodings are added to the input embeddings. These encodings are typically sinusoidal functions of varying frequencies, allowing the model to capture the relative positions of tokens in the sequence.
Positional encodings are added to the input embeddings to provide information about the position of each token in the sequence. The positional encoding for a token at position is calculated as:
where is the dimension index and is the dimensionality of the model. These encodings are added to the input embeddings to form the final input to the transformer.
Here is a Python implementation from this article:
pythonimport numpy as np import matplotlib.pyplot as plt def getPositionEncoding(seq_len, d, n=10000): P = np.zeros((seq_len, d)) for k in range(seq_len): for i in np.arange(int(d / 2)): denominator = np.power(n, 2 * i / d) P[k, 2 * i] = np.sin(k / denominator) P[k, 2 * i + 1] = np.cos(k / denominator) return P P = getPositionEncoding(seq_len=4, d=4, n=100) print(P)
In this code:
seq_lenis the length of the input sequence.dis the dimensionality of the model, which is the size of the input embeddings.nis a scaling factor, typically set to 10000, to ensure that the positional encodings have a wide range of frequencies.
The function getPositionEncoding generates a matrix of positional encodings for the input sequence. Each position in
the sequence is encoded using a combination of sine and cosine functions with different frequencies.
output[[ 0. 1. 0. 1. ] [ 0.84147098 0.54030231 0.00999983 0.99995 ] [ 0.90929743 -0.41614684 0.01999867 0.99980001] [ 0.14112001 -0.9899925 0.0299955 0.99955003]]
Self-Attention Mechanism
The self-attention mechanism allows the model to weigh the importance of each token in a sequence relative to others. This is achieved by computing query (Q), key (K), and value (V) vectors for each token. These vectors are learned projections of the input embeddings.
- Query (Q): Represents the current token for which we want to compute the attention scores.
- Key (K): Represents all the tokens in the sequence that the current token will attend to.
- Value (V): Represents the actual values of the tokens that will be used to compute the weighted sum based on the attention scores.
The attention score is calculated using the formula:
Here, is the dimensionality of the key vectors, and the softmax function ensures that attention scores sum to 1. The self-attention mechanism enables the model to focus on different parts of the sequence when encoding a particular token, allowing it to capture complex dependencies between tokens.
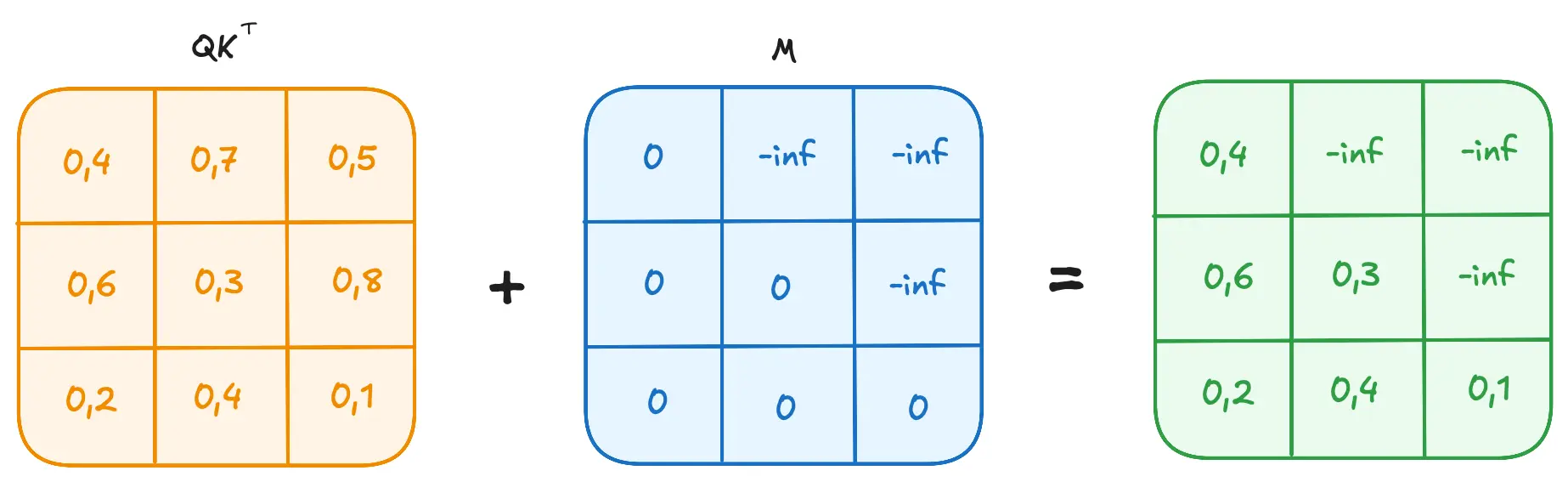
Masked Self-Attention
In certain scenarios, such as during the training of the decoder in a sequence-to-sequence model, it is crucial to
prevent the model from attending to future tokens. This is achieved through masked self-attention. In masked
self-attention, a mask is applied to the attention scores to hide future tokens. The mask is typically a matrix where
the upper triangular part is set to negative infinity (-inf), and the lower triangular part, including the diagonal,
is set to zero.
The masked self-attention mechanism can be described as:
where is the mask matrix. The softmax function will convert the -inf values to zero, effectively removing the
influence of future tokens. This ensures that the model only attends to the current and previous tokens, maintaining the
autoregressive property.
Multi-Head Attention
Multi-head attention extends self-attention by performing attention operations multiple times in parallel with different learned projections of , , and . The outputs are concatenated and linearly transformed, enabling the model to attend to different parts of the sequence simultaneously. Multi-head attention allows the model to capture different types of relationships between tokens by projecting the input vectors into multiple subspaces. The output of the multi-head attention is calculated as:
where and , , , and are learned projection matrices. The number of heads is a hyperparameter of the model.
Feed-Forward Neural Networks
Each layer in the transformer contains a feed-forward neural network (FFN) that applies two linear transformations with a ReLU activation in between. The FFN operates independently on each position, allowing for non-linear transformations and richer representations. The FFN is applied to each position separately and identically, enabling the model to capture complex relationships between tokens. The feed-forward network is defined as:
where , , , and are learned parameters. The feed-forward network is applied to the output of the multi-head attention mechanism.
Add & Norm Mechanism
The "Add & Norm" mechanism ensures stability during training by:
- Adding residual connections around the self-attention and FFN blocks.
- Applying layer normalization to stabilize activations and improve gradient flow.
Residual connections address the vanishing gradient problem by allowing the gradient to flow directly through the network layers. Layer normalization ensures that the inputs to each layer have a consistent scale, which helps to stabilize the training process. The add and norm mechanism is defined as:
where is either the self-attention or the feed-forward network.
Encoder Workflow
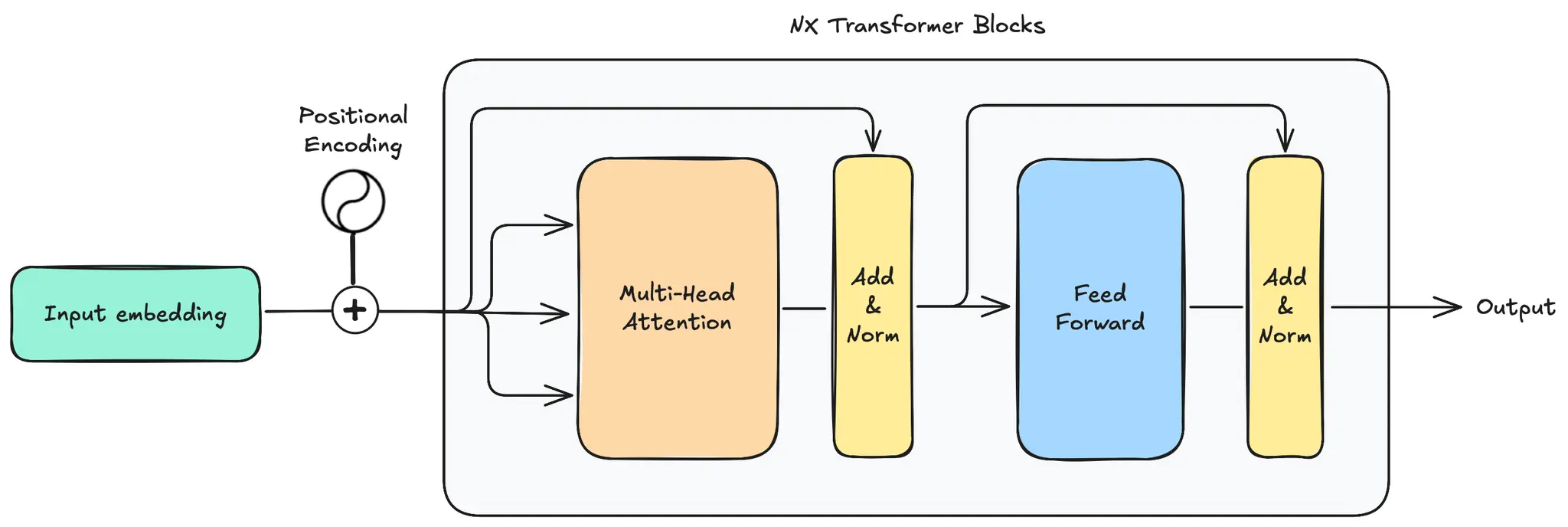
The encoder in a transformer model processes input data through a series of identical layers, as illustrated above. Here’s a streamlined breakdown:
- Input Embedding: Converts raw input data into dense vector representations.
- Positional Encoding: Adds positional information to embeddings to capture the order of tokens.
- Multi-Head Attention: Each token attends to every other token, capturing contextual relationships.
- Add & Norm (First Layer): Adds the output of the multi-head attention to the original input and applies layer normalization.
- Feed-Forward Network: Applies two linear transformations with a ReLU activation to model complex interactions.
- Add & Norm (Second Layer): Adds the output of the feed-forward network to its input and applies layer normalization.
- Output: Passes the processed data to the next transformer block or to the decoder/classification head.
This workflow is repeated across multiple encoder layers, allowing the model to learn increasingly abstract and complex representations of the input.
Decoder Workflow
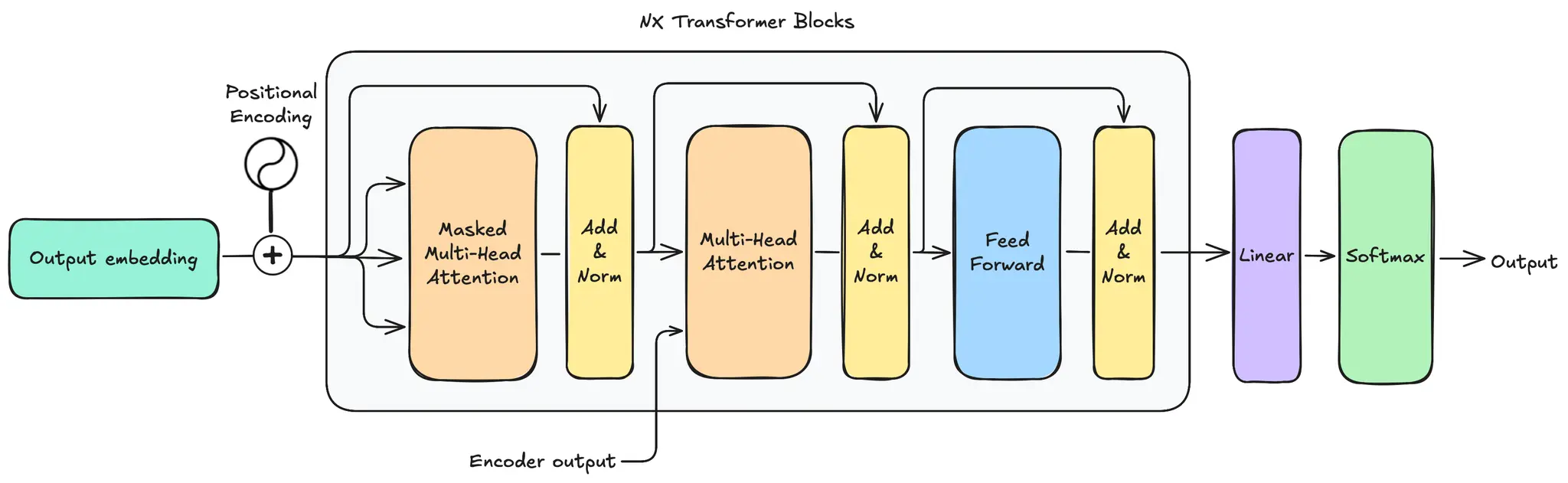
The decoder in a transformer model is designed to generate output sequences by attending to both the input sequence (encoder output) and the previously generated outputs. Here’s a step-by-step explanation of the workflow:
- Output Embedding: The target sequence tokens are converted into dense vector representations that capture semantic meaning.
- Positional Encoding: Positional information is added to embeddings to encode the order of the sequence.
- Masked Multi-Head Attention: The decoder attends to previous tokens in the target sequence, using causal masking to prevent access to future tokens.
- Add & Norm: A residual connection is applied, followed by layer normalization for stability.
- Multi-Head Attention: This layer attends to the encoder’s output, focusing on relevant parts of the input sequence for the current decoding step.
- Add & Norm: Another residual connection and normalization stabilize the output.
- Feed-Forward Network: A fully connected network applies two linear transformations with a ReLU activation to refine the output.
- Add & Norm: A final residual connection and normalization are applied to maintain consistent processing.
- Linear Layer: The refined output is mapped into the vocabulary space using a linear transformation.
- Softmax: The logits are converted into probabilities for each token in the vocabulary.
- Output: The token with the highest probability is selected as the predicted token, completing the decoding process.
This workflow is repeated across multiple decoder layers, progressively refining the output at each step.
Notable Transformer Models
BERT
Bidirectional Encoder Representations from Transformers (BERT) is designed for understanding the context of words within a sentence. It uses a transformer encoder and is trained with masked language modeling and next-sentence prediction objectives. BERT excels at tasks requiring a deep understanding of text, such as question answering and sentiment analysis. The model is pre-trained on a large corpus of text and then fine-tuned on specific tasks, allowing it to capture the nuances of language.
GPT
Generative Pre-trained Transformer (GPT) focuses on text generation tasks. It uses a transformer decoder and is trained in an autoregressive manner, predicting the next token based on prior tokens. GPT has been scaled into multiple versions, with GPT-3 and GPT-4 achieving state-of-the-art results in text generation, summarization, and more. The model is pre-trained on a massive dataset of text and can generate coherent and contextually relevant text.
T5
Text-to-Text Transfer Transformer (T5) is a versatile model that treats every NLP task as a text-to-text problem. It uses a transformer architecture with both an encoder and a decoder, allowing it to handle a wide range of tasks, including translation, summarization, and question answering. T5 is pre-trained on a diverse set of text data and fine-tuned on specific tasks, enabling it to achieve state-of-the-art results on various benchmarks.
Conclusion
Transformers represent a paradigm shift in machine learning, enabling breakthroughs in NLP and beyond. By leveraging self-attention and parallel processing, they overcome the limitations of RNNs and scale effectively to massive datasets. Models like BERT, GPT, and T5 have showcased the versatility and power of transformers, paving the way for further innovation in AI research.